1. Java 11のnull
Javaではintやbooleanなどのプリミティブ型の値はnullになることはない。
なので、参照型の値だけを考えれば良い。
ただし、プリミティブ型のラッパークラス(IntegerやBooleanクラスなど)のボクシングやアンボクシングには気をつける必要がある。
nullオブジェクトパターン
何かキーが押されたら、そのキーに対応した処理を実行する、という例を考えてみよう:
...
public final class Main {
private final Map<Character, Runnable> map;
public Main() {
map = new HashMap<>();
map.put('h', () -> moveCursorLeft());
map.put('j', () -> moveCursorDown());
map.put('k', () -> moveCursorUp());
map.put('l', () -> moveCursorRight());
}
public void handleKeyInput() {
var c = getPressedKey();
var action = map.get(c);
// actionはnullの可能性があるので、次のメソッド呼び出しは
// NullPointerExceptionをスローするかもしれない
action.run();
}
/**
キーボードの押されたキーの文字を返す.
キーが押されてない場合は、押されるまでブロックする.
@return
押されたキーの文字
*/
private char getPressedKey() {
...
}
...
Mapインターフェースのget(Object)メソッドはnullを返す可能性があるので、
戻り値がnullかどうかを確認するコード、
すなわちnullチェックを追加する必要がある:
private void handleKeyInput() {
var c = getPressedKey();
var action = map.get(c);
if (action == null) {
// 登録されてないキーは何もしない
return;
}
action.run();
}
このnullチェックは何を表しているのだろうか。
Mapの代わりにif—else if—elseやswitchを用いて実装すれば、
そのときにelseやdefaultで記述する処理が、
このnullチェックに相当することがわかる
(#20「分岐よりサブタイピングを選ぶ」を参照)。
なお、
ifやswitchでは循環的複雑度(cyclomatic complexity)が上昇するし、 テストも面倒になる。 さらにelseやdefaultの書き忘れはコンパイル時も実行時も直ちにはエラーにはならないので、 間違いに気づきにくい。
さて、このnullチェックは次のように消すことができる:
private static final Runnable DO_NOTHING = () -> {};
...
private void handleKeyInput() {
var c = getPressedKey();
// もちろん、DO_NOTHINGの代わりに空のメソッドのメソッド参照を渡してもよい
var action = map.getOrDefault(c, DO_NOTHING);
action.run();
// 実際、actionは不要で次のように書いて良い:
//
// map.getOrDefault(c, DO_NOTHING)
// .run();
}
get(Object)の代わりにgetOrDefault(Object, V)を用いた。
対応する操作が存在しない文字に対しては、
nullではなく、
DO_NOTHINGという何もしないRunnableが返ってくる。
文字に操作が関連付けられているかどうかに関わらず、返された操作を実行するだけでよくなった。
そして、nullチェックのためのifはライブラリ側におっかぶせることで消失した。
このように、
nullの代わりに特別なオブジェクトを使う技法をnullオブジェクトパターン [1] と呼ぶ。
書籍 Refactoring [2] ではIntroduce Null Objectで紹介されている。

いつものことだが、このパターンも銀の弾丸ではない。
何もしないRunnableやConsumerみたいなオブジェクトが使えるパターンではうまくいくことが多い。
しかし、FunctionやSupplierみたいなオブジェクトを使うパターンは向いていないこともある。
次のような例を考えてみよう:
interface Color {
/**
指定した名前にマッチするColorインスタンスを返す.
@param name
...
@return
{@code name}にマッチするものが無ければ{@code null},
そうでなければマッチしたインスタンス.
*/
static Color findByName(String name) {
...
}
/**
RGBを24ビットで表した整数値を返す.
@return
...
*/
int getRgb();
}
findByName(String)は、
Mapのget(Object)と同様、
検索系の操作の定番で、
欲しいものが無かったらnullを返す。
呼び出す側のコードは次のようになる:
var yellow = Color.findByName("YELLOW");
// yellowはnullの可能性があるので、次のメソッド呼び出しは
// NullPointerExceptionをスローするかもしれない
var rgb = yellow.getRgb();
nullチェックを追加すれば終わりだが、
先ほどのMapの例と同様に、
nullオブジェクトのようなものを導入してみるとどうなるのだろうか:
interface Color {
/** 不正なカラーを表す. */
static final Color INVALID = () -> -1;
/**
指定した名前にマッチするColorインスタンスを返す.
@param name
...
@return
{@code name}にマッチするものが無ければ{@link INVALID},
そうでなければマッチしたインスタンス.
*/
static Color findByName(String name) {
...
}
...
不正な色のRGB値といってもよくわからないので、 定番の−1でも返しておくことにした。 すると、これを使う側は次のようになる:
var yellow = Color.findByName("YELLOW");
var rgb = yellow.getRgb();
// 結局、rgbが-1かどうかを調べる必要がある
rgbが−1かどうかをチェックしなくても、続くコードを実行できてしまう。
状況によっては、このようなコードはかえって危険である。
必要なnullチェックが抜けていたら例外をスローし、
以降のコードを実行しない方が幸せなこともあるからだ。
そう、問題はnullかどうかではなく、必要なチェックをするかどうかだ。
だが、そのチェックこそ、
このようなnullオブジェクトパターンもどきがうまくいかない理由である。
findByName(String)メソッドの中身を想像するに、
その中で次のような本質的なチェックが既に実装されているはずだ:
interface Color {
...
static Color findByName(String name) {
...
// 次のifが本質的なチェック
if (nameに関連するColorオブジェクトが見つからない) {
// パスA
return INVALID;
}
// パスB
return 見つかったColorオブジェクト;
}
...
そして、呼び出し側のコードのチェックは次のようになっているはずだ:
var yellow = Color.findByName("YELLOW");
var rgb = yellow.getRgb();
if (rgb == -1) {
// 処理Aを実行
} else {
// 処理Bを実行
}
つまり、本質的なチェックでパスAを通過したならば処理Aを、
パスBならば処理Bを、呼び出し側は決定的に実行する(deterministicである)。
ここまできたら、もう気が付いたと思うが、
findByName(String)に追加で「処理A」と「処理B」も渡してしまえば、
呼び出し側は戻り値もそのチェックも不要になる。
要するに、次のような形に変えてやればよい:
interface Color {
...
static void findByName(String name, 処理A, 処理B) {
...
if (nameに関連するColorオブジェクトが見つからない) {
// 処理Aを実行
return;
}
// 処理Bを実行 with 見つかったColorオブジェクト
}
...
}
...
// 呼び出し側は戻り値もそのチェックも不要
Color.findByName("YELLOW", 処理A, 処理B);
Optionalクラス
この手の操作、つまり「値の有無の情報と、 さらに値がある場合はその値を取得する」操作は、 次のやり方で記述できる:
- 型
Tの値と値の有無を表すboolean値を保持するインスタンスを戻り値とする - 戻り値をやめて、値を受け取るための
Consumer<T>と値が無いことを知らせるRunnableを引数に追加する
前者は言語によっては例えばタプルを使っても実現できる。
後者は単にコールバックで結果を得るだけだ。
仮にPair<K, V>のような酷いクラスを利用可能だとすると、
先ほどのfindByNameメソッドは次のようなコードになる:
interface Color {
static Pair<boolean, Color> findByName(String name) {
...
}
static void findByName(String name,
Consumer<Color> found,
Runnable notFound) {
...
}
...
しかし、この調子でAPIを記述していけば、 コードはすぐにボイラープレートまみれになるだろう。
幸い、Javaにはこれらの操作をカプセル化したOptionalクラス†1がある。
先ほどの例をそのOptionalクラスを使って書き直してみよう:
†1
OptionalはJava 8から追加された。
interface Color {
/**
指定した名前にマッチするColorインスタンスを返す.
@param name
...
@return
{@code name}にマッチするColorインスタンスを
含む{@link Optional<T> Optional}, または
空のOptional (マッチするものがない場合).
*/
static Optional<Color> findByName(String name) {
...
}
}
使う側は次のようになる:
var yellow = Color.findByName("YELLOW");
yellow.ifPresent(c -> {
var rgb = c.getRgb();
System.out.println("yellow: rgb=" + rgb);
});
// あるいは、次のように書いても良いが...
var blue = Color.findByName("BLUE");
if (blue.isPresent()) {
var rgb = blue.get().getRgb();
System.out.println("blue: rgb=" + rgb);
}
ifPresent(Consumer)は値が存在すれば、
その値をパラメータとして引数のConsumerを実行する。
存在しなければ何もしない。
存在のチェックをライブラリ側におっかぶせることで、うまくいく。
逆に、isPresent()とget()の組み合わせは最悪で、
結局isPresent()のチェックを忘れるとget()で例外をスローするだけだ。
ただの言葉遊びでしかない。
Optional<T>には、 そのほかにも、orElse(T)、orElseGet(Supplier)のようなデフォルト値、またはデフォルト値を返すラムダ式、 を指定して値を取り出すメソッドなど、がある。
このOptionalクラスのような型を選択型†2(option type)[3]
と呼ぶ。
†2 不確実型(maybe type)と呼ぶこともある。
Javaにはないが、
他の言語の中にはnull許容型(nullable type)があるものもある。
これは選択型と少しだけ異なる。
選択型ではOptional<Optional<T>>とネストできるが、null許容型はそれができない。
null許容型については次のC#のパートで取り扱う。
少し話を逸らす。YELLOWが見つかったら...、 BLUEが見つからなかったら...、 のような簡単な課題はより簡単に書けるようになったかもしれない。 しかし、現実の問題はより難しい。 YELLOWとBLUEの両方が見つかったら...、となっただけで、 簡単にはいかなそうな匂いを嗅ぎとれただろうか。 次のように書けばいい、と考えるかもしれない:
var yellow = Color.findByName("YELLOW"); yellow.ifPresent(c1 -> { var blue = Color.findByName("BLUE"); blue.ifPresent(c2 -> { // c1, c2を使った処理 ... }); });確かにそうかもしれないが、では色が2つではなく、 n 個になったらどうすればよいだろうか。 この後にヒントもあるので、ちょっと考えてみてほしい。
集合とnull
Optionalクラスは、所詮nullチェックをカプセル化しただけのクラス、なのだろうか。
その本質はいったい何か考えてみよう。
次のストリームAPIの使用例をみてみよう:
var firstFavorite = List.of("foo", "bar", "baz")
.stream()
.filter(matchesFavorite)
.findFirst();
firstFavorite.ifPresent(s -> { ... });
// 結果的に次と同じ
List.of("foo", "bar", "baz")
.stream()
.filter(matchesFavorite)
.findFirst()
.ifPresent(s -> { ... });
matchesFavoriteは適当なPredicate<String>とする。
StreamインターフェースのfindFirst()は(良く考えられていて)この場合Optional<String>のインスタンスを返すので、
値の有無のチェックが必要になる。
あえてfindFirst()を使わないで同じことをやってみると、
次のようになる:
var favoriteList = List.of("foo", "bar", "baz")
.stream()
.filter(matchesFavorite)
.limit(1)
.collect(Collectors.toList());
以前との違いは、戻り値の型がOptional<T>からList<T>になったことだ。
リストといっても、
要素の数は0か1、カッコ良く言うと高々1個である。
したがって、実質的にこのList<T>はOptional<T>と同じだから、
次のように続けることができる:
favoriteList.forEach(s -> { ... });
// または
for (var s : favoriteList) {
// このループは高々1回しか実行されない
...
}
// あるいは、次のように書いても良いが...
if (favoriteList.size() != 0) {
var s = favoriteList.get(0);
...
}
したがって、
あえてfindFirst()を使わないバージョンは次のように書けることがわかる:
List.of("foo", "bar", "baz")
.stream()
.filter(matchesFavorite)
.limit(1)
.forEach(s -> { ... });
もちろん、
Optional<T>があるJavaでこのようなコードを書いていたら、
コードレビューで直されるだけだ。
Optional<T>が長さが高々1である特殊なList<T>とみなせることがわかれば、
このようなコードは忘れて良い。
Optionalの代わりにListを使えるとしても、ArrayListでラップしていたらオーバーヘッドが大きい。 要素が最大1つという制約を用いるListの実装クラスがあれば、Optionalと同じくらいの軽さで実現できる。 だが、そのようなものを自前で実装しなくても、 実はOptionalがデビューするずっとから、その目的に合致するCollections.singletonList(T)が追加されている。 これとCollections.emptyList()を使ってOptionalのようなことが実現できる (Collections.singleton(T)とCollections.emptySet()でも良いが、Setから要素を取り出すのは面倒なので、ここでの説明にはListを用いた)。
さて、これらを書籍 Effective Java [4] の Item 43: Return empty arrays or collections, not nulls と合わせてまとめると、次のようになる:

| インスタンスの個数 | 型 | null/その代わりに... |
|---|---|---|
| 高々1個 | T |
null |
| 高々1個 | Optional<T> |
Optional<T>.empty() |
| 0個以上 | T[] |
public static final T[] EMPTY = {}; |
| 0個以上 | List<T> |
Collections.emptyList() |
| 0個以上 | Stream<T> |
Stream<T>.empty() |
参照がnullかどうか、
というのは配列の要素数が0かどうかと同じレベルの問題である。
「intだとメモリもったいないからshortにする」のと同じノリで、
要素数が高々1個の場合、配列だと重たいから参照を使う†3にすぎない。
だから、nullを撲滅しようと
俺が悪いんじゃない、全部
nullが悪いんです。 null安全な言語を使わないからダメなんです。
と叫んでる人たちは、 目的が達成された暁には、 今度はサイズチェックが必要な固定長配列も撲滅するのだろう。
†3 細かいことを言うと、配列の方が表現力は高い。 配列の場合は値の有無の情報(配列の長さが0または1)と値そのものは独立しているので、 配列の要素そのものを
nullにして、「値有り、値はnull」を表現できる。 一方、値の有無をnull参照か否かで表す場合は、値そのものをnullとすることは不可能である。
実際のところ、
CやC++ではNULLポインタの間接参照
(indirectionまたはdereferencing)
は未定義の振る舞いだからあってはならないのである(#28「未定義の振る舞い」を参照)。
Javaはnullを間接参照したときにNullPointerExceptionをスローすると定義しているので、
CやC++のNULLと比べればJavaのnullは安全である。
そういった違いがあるものを同列に扱っても意味はない。
Optionalの問題点
では、高々1個にはOptionalを使えば全てが解決するのか。
もちろん、そんなわけはない。
それはnullの代わりに空の配列を返すのと同様で、
次のような問題がある:
Optionalはプリミティブ型ではなく、参照型であるisPresent()で確認せずにget()することができてしまう- 標準ライブラリには
nullを返したり受けとる昔のAPIがたくさん残っている - すべてを
Optionalにすると実行時の性能が犠牲になる
最初の問題はコンパイラがOptionalを特別扱いしないことに起因する。
Optional型と思ったらnullだった、ということが普通に起こりうる。
例えば、次のようなコードはシュールだが実用性はない:
Optional<String> maybeString = null;
あるいは:
public Optional<String> getMaybeString() {
return null;
}
当たり前だが、戻り値の型がOptional<T>であるメソッドがnullを返したり、
Optional<T>型のパラメータを受け取るメソッドにnullを渡すこともできる。
かといって、現状のJavaでnullがOptional<T>.empty()にボクシングされてもスッキリはしないが。
2番目の問題も、コンパイラの問題だ。
コンパイル時に静的解析で発見できるバグを、
実行時にNoSuchElementExceptionが発生するまで発見を遅らせる可能性がある。
3番目の問題は、過去の資産との向き合い方である。
昔のAPIとはnullで、
最新のAPIとはOptionalで正しく統合しなくてはならない。
最後の問題は、 いつものことだが、 実行時の性能を犠牲にすることを許さない人が大勢いる、 ということだ。
コンパイラの静的解析
コンパイラの静的解析(データフロー解析)と、 ソースコードにメタデータをアノテーションすることを組み合わせることで、 参照型の値のnullチェックが適切であるかをコンパイル時に知ることができる。 JDKには今のところ含まれていないが、 静的解析ツールでは次のようなものがある:
また、次のIDEも同様な仕組みに対応している:
- IntelliJ IDEA
- Eclipse
- Android Studio
ただし、アノテーションで使用するクラスは今のところ標準化†4されていない。
そのため、各実装で独自の似たようなアノテーションクラス
(@NonNull、@NotNull、@Nonnullなど)
が定義されており、互換性がないことに注意する必要がある。
†4 JSR-305/308で標準化しようとしている。 なぜ乱立してるかは次を参照:
https://stackoverflow.com/questions/4963300/which-notnull-java-annotation-should-i-use
IntelliJ IDEAの実装を例にすると、
@NotNullと@Nullableで次のようにフィールド、
パラメータ、
戻り値などをアノテートする:
public final class ContactInfo {
private @NotNull String name;
private @NotNull List<@NotNull String> mailList;
private @Nullable Integer age;
public ContactInfo(@NotNull String name,
@NotNull List<@NotNull String> mailList,
@Nullable Integer age) {
this.name = name;
this.mailList = Collections.unmodifiableList(mailList);
this.age = age;
}
...
public @Nullable String getPrimaryMail() {
var list = mailList;
return list.size() == 0 ? null : list.get(0);
}
...
public @Nullable Integer getAge() {
return age;
}
}
そして、このContactInfoクラスを使う次のコードを用意する:
public final class Main {
private static void sendMail(@NotNull String mailAddress,
@NotNull String name) {
System.out.println(mailAddress + " " + name);
}
public static void main(String[] args) {
var listContainingNull = new ArrayList<String>();
listContainingNull.add(null);
var infoList = List.of(
new ContactInfo("Jack", listContainingNull, null),
new ContactInfo("Jack", List.of("jack@example.com"), null),
new ContactInfo("Kim", Collections.emptyList(), 18));
infoList.stream()
.filter(i -> i.getAge() < 20)
.forEach(i -> sendMail(i.getPrimaryMail(), i.getName()));
}
}
IntelliJ IDEAのAnalyze ➜ Inspect Code...を実行すると、 次のような結果が得られる:
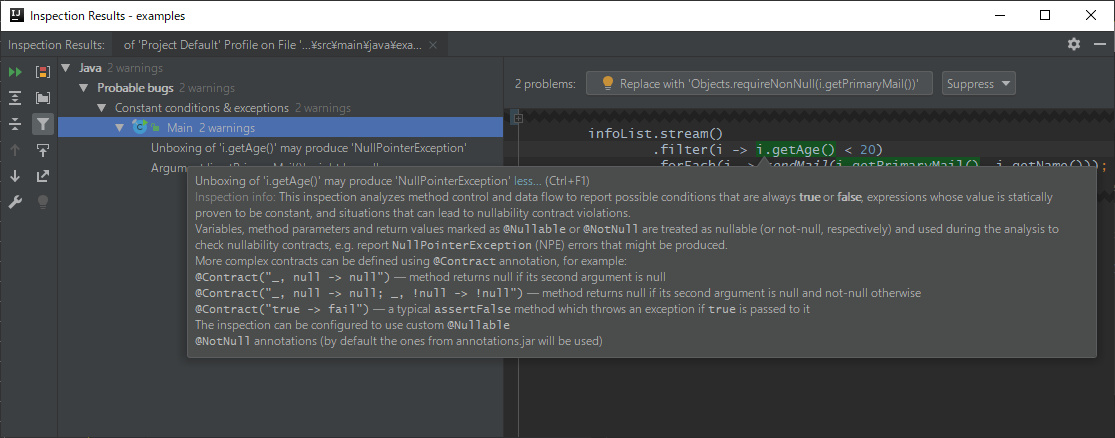
確かに、i.getAge()はnullになりえるのでnullチェックが必要なのに、
nullチェック無しでアンボクシングしているから指摘は正しい。
同様に、次の指摘:
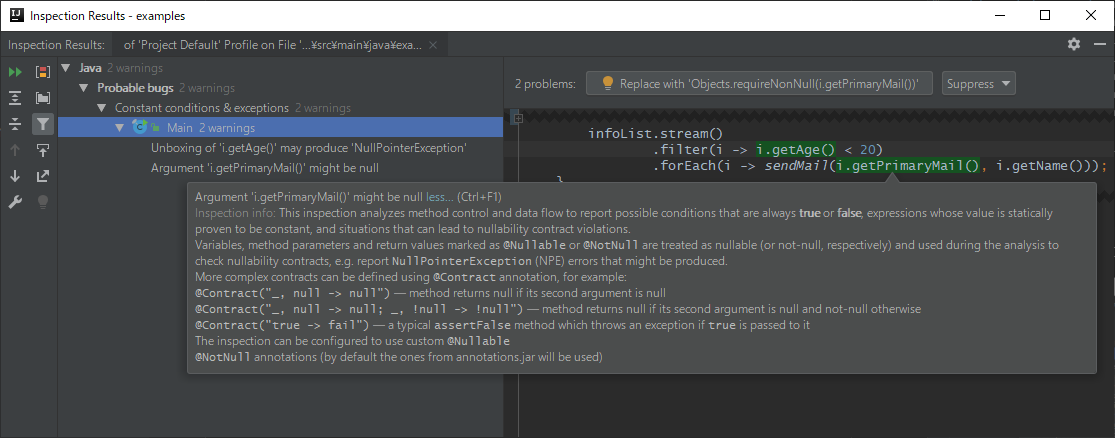
sendMailの最初のパラメータにi.getPrimaryMail()の戻り値を指定しているが、
これもnullになりうる値をnullであってはならないパラメータに渡しているので、
指摘通りである。
しかしながら、
ContactInfoのコンストラクタの第2パラメータにlistContainingNullを渡すところはスルーしている。
どうやら、
List<@NotNull String>のような型パラメータに対するアノテーションは機能していないようだ。
とはいえ、このようなアノテーションが標準化されて、かつ実用的†5になれば、
妙なボイラープレート(publicメソッドの最初に引数の値がnullかどうか確認する儀式)と
そのためのAPIは不要になる。
†5 静的解析は完璧ではない。偽陽性(false positive)や偽陰性(false negative)はゼロにはならない。また、メタデータは人が付与するため、APIが間違ってアノテートされると、その後は大惨事が起きる。
水際対策
残念ながら、標準ライブラリの必要なAPI全てにメタデータが付加され、コンパイラが警告を出せるようになるまでは、nullにまつわるアノテーションは概念実証(Proof of Concept: PoC)でしかない。
Javaに限らずnull安全でない言語では、
現実的にはnullに対して次のような水際対策でnullの上陸を食い止めるしかない:
- できるだけ
nullを使わない nullを返す/受け取る可能性があるAPIを使用したら、 速やかにnullかどうか確認する(nullの確認を先送りしない)nullを手にしてしまったら、 それを適切な別の表現に変換するなどして、 速やかに処分する(nullの処分を先送りしない)
nullの処分の先送りとは、例えば次のようなことである:
nullを何の罪も無い他のオブジェクトにおっかぶせる(Optional<T>のofNullable(T)メソッドなど、そのためのクラスに渡すのはよい)nullを別の型に伝搬する†6- 不適切なnullオブジェクトに変換する
NullPointerExceptionをキャッチする†7
†6 別の型に伝搬する例:
(s == null) ? null : s.getValue()
†7
NullPointerExceptionに限らず、RuntimeExceptionとその派生の例外はキャッチすべきではないが...
特にJavaでは、nullかもしれない参照はすぐにOptional.ofNullable(T)でラップして、
そのまま確認、処分すればよい。ラップしたまま先送りしないこと。
nullの源泉
水際対策ができれば、あとは自分がnullをなるべく生み出さないようにする。Javaの代表的なnullの源泉は、未初期化のフィールド、配列の生成、未初期化のローカル変数、といったところだろう:
// 未初期化のフィールド
private String name;
public void foo() {
// 配列の生成(要素は全てnull)
var array = new Object[SIZE];
// 未初期化のローカル変数
String s;
...
}
すべてのクラスを不変にはできない†8ので、
インスタンスの状態に応じて値が変化するフィールドは当然存在する。
しかし、そうしたフィールドがnullになるべき必然性はない。
例えば、nullが値を設定されていないことを表す、というのであれば、
nullを使う代わりに、
フィールドの型をTからOptional<T>に変えて、
それを表すためにOptional<T>.empty()をさしておくこともできる。
†8 簡単な例は、相互参照する2つのインスタンス、循環参照のリストなど。
そのインスタンスのどの状態においても特定のフィールドが
nullでありうる、というのなら、そのフィールドへのアクセスすべてについて
nullチェックが必要であり、Optional<T>でラップすることに意味がある。
そうではなく、
インスタンスの状態によってそのフィールドがnullまたは非nullであることが決まっていることもある。
例えば、あるプライベートのインスタンスメソッドを呼び出している間、
特定のフィールドが非nullであることを保証している、
という状況にあるなら、クラスを分割する、ステートパターンを適用するなど、
設計を見直す方がいいかもしれない。
配列もできるだけストリームAPIの終端操作で生成し、 それでは実現できないもの†9だけを許容すべきである。
†9 直ぐに思い浮かぶのはハッシュテーブルの実装など。
最後のローカル変数だが、基本的にローカル変数は宣言時に初期値を必ず代入すること。 新入社員やそれに準じるスキルの方々が、 次のようなコードを書いてドヤ顔をしているのをよくみかける:
String s;
if (state == State.A) {
s = ...
} else {
s = ...
}
三項演算子(またはJava 12のswitch式)で書ける場合もあるし、
それができない場合はvar s = method();のように値を返すメソッドに分離する、
あるいはそれをメソッドに分けるとやたらパラメータが多くなるのであれば、
SupplierかFunction(ラムダ式)を定義して、その式の戻り値を代入する、
などを検討してみる(C#ならラムダ式の代わりにローカル関数を使ってもよい)。
未初期化のローカル変数には、似たようなケースが多々ある。 例えば、
try—catchでtryの直前に変数を宣言だけしておいて、tryブロックの中でその変数に値を代入するケースも同様である。